Understanding word embedding-based analysis
Word embeddings are real-valued vector representations of words or phrases. They operate under the distributional hypothesis theory, where texts with similar meanings are derived to have similar representations, and thus to be closer to one another in the vector space. Classically, individual words were mapped into a vector space where each word has its own unique vector using techniques such as LSA (Landauer, Foltz & Laham, 1998), word2vec (Mikolov et al., 2013), and GloVe (Pennington, Socher & Manning, 2014) (note that representations for larger units of text can be generated by summing or averaging the individual constituent word vectors). More recently, entire phrases, sentences, and paragraphs may be mapped onto a single vector using techniques such as ELMo (Peters et al., 2018), BERT (Devlin et al., 2018), and GPT-3 (Brown et al., 2020). The underlying idea is that the totality of information about all the word contexts in which a given word does and does not appear provides a set of mutual constraints that largely determines the similarity of meaning of words and set of words to each other.
Word and discourse meaning representations derived by word embeddings have been found capable of simulating a variety of human cognitive phenomena, ranging from acquisition of recognition vocabulary to sentence-word semantic priming and judgments of essay quality. Thus, a common metric for comparing texts is by using a cosine distance between vector representations. Cosine distances can range from -1 to 1, with values closer to 1 being the most similar.
LSA
Latent Semantic Analysis (LSA) is a theory and method for extracting and representing the contextual-usage meaning of words by statistical computations applied to a large corpus of text. LSA is based on singular value decomposition, a mathematical matrix decomposition technique closely akin to factor analysis that has recently become applicable to databases approaching the volume of relevant language experienced by people.
The first step is to represent the text as a matrix in which each row stands for a unique word and each column stands for a text passage or other context. Each cell contains the frequency with which the word of its row appears in the passage denoted by its column. Next, the cell entries are subjected to a preliminary transformation in which each cell frequency is weighted by a function that expresses both the word's importance in the particular passage and the degree to which the word type carries information in the domain of discourse in general.
Next, LSA applies singular value decomposition (SVD) to the matrix. This is a form of factor analysis, or more properly the mathematical generalization of which factor analysis is a special case. In SVD a rectangular matrix is decomposed into the product of three other matrices. One component matrix describes the original row entities as vectors of derived orthogonal factor values, another describes the original column entities in the same way, and the third is a diagonal matrix containing scaling values such that when the three components are matrix-multiplied, the original matrix is reconstructed. There is a mathematical proof that any matrix can be decomposed perfectly, using no more factors than the smallest dimension of the original matrix. When fewer than the necessary number of factors are used, the reconstructed matrix is a least-squares best fit. One can reduce the dimensionality of the solution simply by deleting coefficients in the diagonal matrix, ordinarily starting with the smallest. (In practice, for computational reasons, for very large corpora only a limited number of dimensions can be constructed.)
The LSA embeddings available on this website were generated in multiple semantic spaces. Note that you cannot compare the same word directly between semantic spaces. The following semantic spaces are available for comparisons:
- General Reading up to XX (TASA). These spaces use a variety of texts, novels, newspaper articles, and other information, from the TASA (Touchstone Applied Science Associates, Inc.) corpus used to develop The Educator's Word Frequency Guide. We are extremely thankful to the kind folks at TASA for providing us with these samples.
This first incarnation of TASA-based spaces breaks out by grade level -- there are spaces for 3rd, 6th, 9th and 12th grades plus one for 'college' level. These are cumulative spaces, i.e. the 6th grade space includes all the 3rd grade docs, the 9th grade space includes all the 6th and 3rd, etc.
The judgment for inclusion in a grade level space comes from a readability score (DRP-Degrees of Reading Power Scale) assigned by TASA to each sample. DRP scores in the TASA corpus range from about 30 to about 73. TASA studies determined what ranges of difficulty are being used in different grade levels, e.g. the texts used in 3rd grade classes range from 45-51 DRP units. For the LSA spaces, all documents less than or equal to the maximum DRP score for a grade level are included, e.g. the 3rd grade corpus includes all text samples that score <= 51 DRP units.
The following are the specifics for each space:
The documents are formatted like this:name grade maxDRP # docs # terms # dims tasa03 3 51 6,974 29,315 300 tasa06 6 59 17,949 55,105 300 tasa09 9 62 22,211 63,582 300 tasa12 12 67 28,882 76,132 300 tasaALL college 73 37,651 92,409 300
[Aaron01.01.01] [P#=1] [DRP=49.889142] [SocialStudies=Yes] [S] who were the first americans? [S] many, many years ago, perhaps 35,000 years ago, life was very different than it is today. [S] at that time, the earth was in the grip of the last ice age. ...
The first tag is the ID for the sample, P# is the number of paragraphs in the sample, DRP score, and then any 'academic area' tags.
The breakdown for samples by academic area (in tasaALL):samples paragraphs LanguageArts 16,044 57,106 Health 1,359 3,396 HomeEconomics 283 403 IndustrialArts 142 462 Science 5,356 15,569 SocialStudies 10,501 29,280 Business 1,079 4,834 Miscellaneous 675 2,272 Unmarked 2,212 6,305 total 37,651 119,627 - HSBio. The High School Biology space is 3318 paragraphs comprising all of the text (34 chapters) from a biology textbook written around the High School to entry college level. It has 11624 unique word types. It does contain a number of words related to anatomy and so may be somewhat appropriate for research on anatomy-related topics.
- Myers Psychology 5th Edition. Myers Psychology 5th Edition is 7135 paragraphs comprising 19 chapters of a college level psychology textbook. It has 23561 unique word types.
- HSBio + Ecology. HSBio + Ecology includes the HS biology space detailed above, as well as a short middle school textbook on ecology. It contains 3429 paragraphs and 12026 unique word types.
- French Spaces. There are 9 french semantic spaces that can be organized in 5 categories:
1 - Newspapers "Le Monde":- Francais-Monde consists of six months (January to June 1993 of "Le Monde" newspapers). It contains 21499 documents, 8613508 tokens, and 170988 unique word types.
- Francais-Monde-Extended consists of six other months (July to December 1993 of "Le Monde" newspapers 1993). It contains 29103 documents, 8468509 tokens, and 175665 unique word types.
- Francais-Total is the concatenation of Francais-Monde + Francais-Livres. It contains 36125 documents, 14279442 tokens, and 223780 unique word types.
- Francais-Livres consists of books published before 1920. It contains 14625 documents, 5665848 tokens, and 118770 unique word types.
- Francais-Livres1and2 consists of books published before 1920, as well as recent books. It contains 119503 documents, 12016753 tokens, and 394332 unique word types.
- Francais-Livres3 is smaller and consists of only recent literature with idioms. It contains 26572 documents, 2566808 tokens, and 96748 unique word types.
- Francais-Contes-Total consists of all traditional tales we have found in electronic format, as well as recent tales also found on web sites. This semantic space is used to study recall or summary of stories by children and adolescents. It contains 14817 documents, 1634428 tokens, and 50330 unique word types.
- Francais-Production-Total contains texts written by children from 7 to 12 years in primary school in Belgium and France. There are 830 docs and 3034 unique terms. This space was created using a stop list of 439 common words. It contains 19755 documents, 910878 tokens, and 41455 unique word types.
- Francais-Psychology consists of texts from a French psychology textbook. It contains 13036 documents, 1308543 tokens, and 44359 unique word types.
word2vec
Word2vec is a method introduced by Mikolov et al. in 2013 for learning a single context-independent embedding for each word in a text corpus. This technique harnesses a neural network to learn either a word given its context (known as the Continuous Bag-of-Words or CBOW approach), or the context given a word (known as the Continuous Skipgram approach). Both variations learn a representation for a word given local context (i.e., a window of neighboring words). This context is a configurable parameter of the model whose size has a notable effect on the resulting vectors. When larger windows are used, the vectors encode more topical information, whereas smaller windows encode more functional and syntactic information. The neural network architecture for word2vec is shown below.
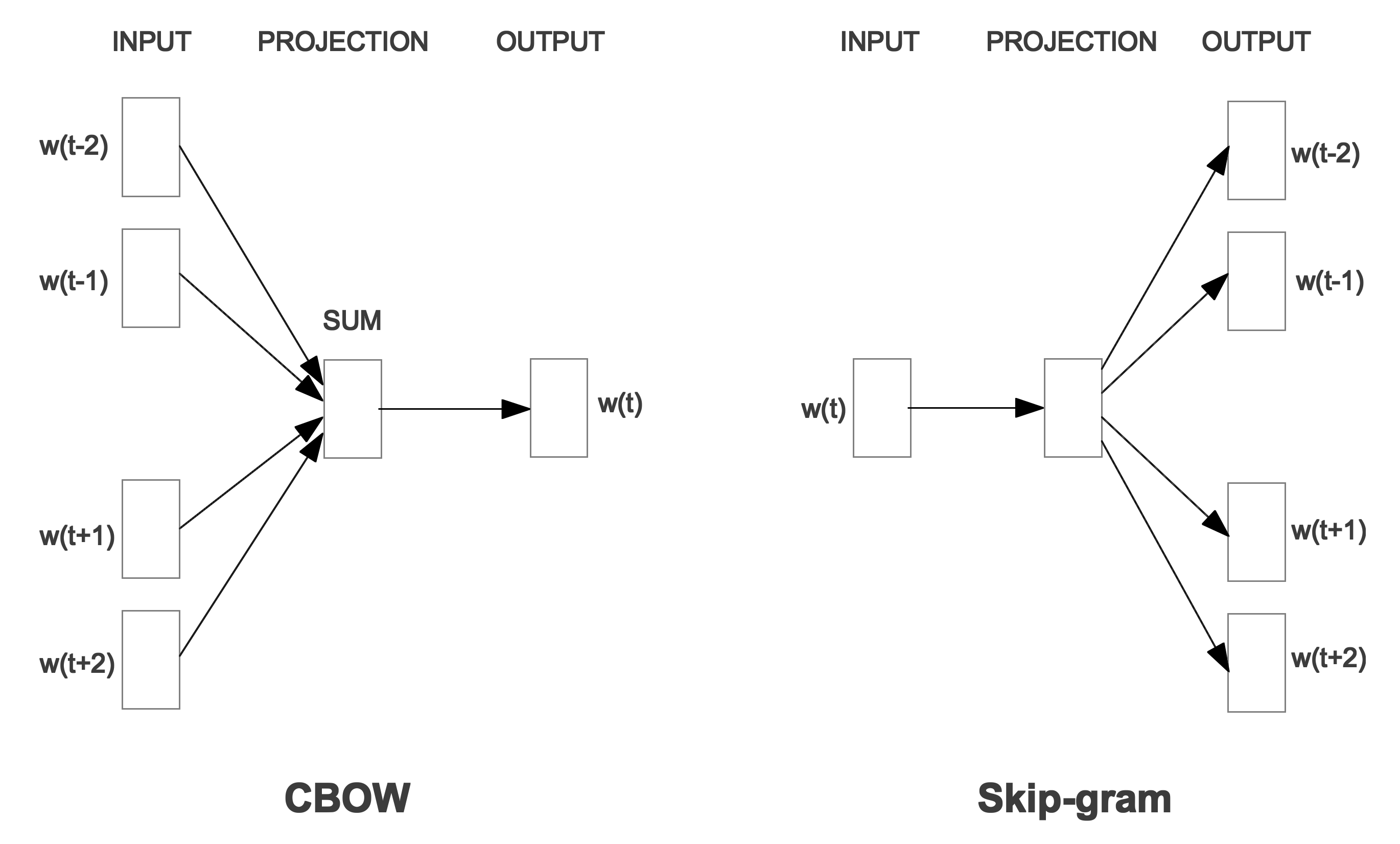
The word2vec embeddings available on this website are the pre-trained vectors generated from the CBOW algorithm with the Google News dataset (about 100 billion words). These vectors are 300-dimensional and encompass a vocabulary of about 3 million words and phrases. The vectors are publically available here.
BERT
Bidirectional Encoder Representations from Transformers (BERT) is a deep learning based language model introduced by Devlin et al. in 2018. The BERT model is pretrained to generate deep bidirectional representations from unlabeled text. The bidirectional component means that it can jointly condition text on both the left and the right context in all layers. It is pretrained on two tasks: masked word prediction and next sentence prediction. The BERT model can be used fully as a machine learning prediction model with the addition of one final fine tuning layer or individual embeddings can be extracted from the model for many purposes.
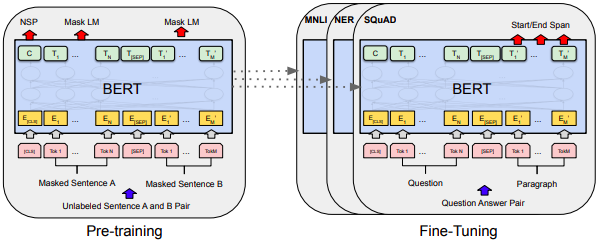
This website contains the original BERT release which was trained on the BooksCorpus (800M words; Zhu et al., 2015) and English Wikipedia (2,500M words). This pretrained model is known as the bert-base-uncased (uncased meaning that the both "word" and "Word" would be represented the same in the encoding) release and is available here.