How to use the website
There are 5 variations of text comparison applications available on this website: matrix, one to many, pairwise, sentence, and nearest neighbors comparisons. Each application is some variation of word embedding cosine distances. Matrix comparison accepts a list of words or documents and the cosine distance between each input is computed against all of the others. One to many comparison accepts a source word or document and a list of other words or documents and it computes the cosine distance between the one source document and each of the other inputs. Pairwise comparison accepts an even numbered list of words or documents and computes the cosine distance between the first and the second, the third and the fourth, the fifth and the sixth, and so on. Sentence comparison accepts a paragraph of text where the cosine distance is computed between each pair of consecutive sentences (as delimited with standard end of sentence punctuation). Finally, nearest neighbors comparison accepts one source word or document and returns the N (as supplied by the user) nearest words in the chosen semantic space, along with their cosine distances to the source document.
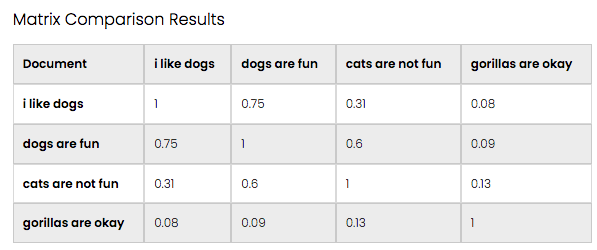
Here we will demonstrate the process of the matrix comparison, first at a high level and then demonstrated within the website interface. The four documents we wish to perform a semantic comparison of are:
- Doc 1: I like dogs,
- Doc 2: Dogs are fun,
- Doc 3: Cats are not fun, and
- Doc 4: Gorillas are okay
The four documents are supplied by the user and first converted to their word embeddings in a chosen embedding space. The system computes the cosine distance between each document to each other document and returns a matrix of distances.

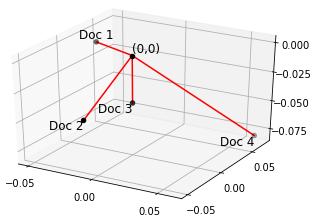
The embedding space representation of the four documents is shown below as vectors in a 3-dimensional space (note however that the true vectors are 300 dimensions each). The cosine distance between vectors is the standard approach for determining the similarity of the embeddings in this space.
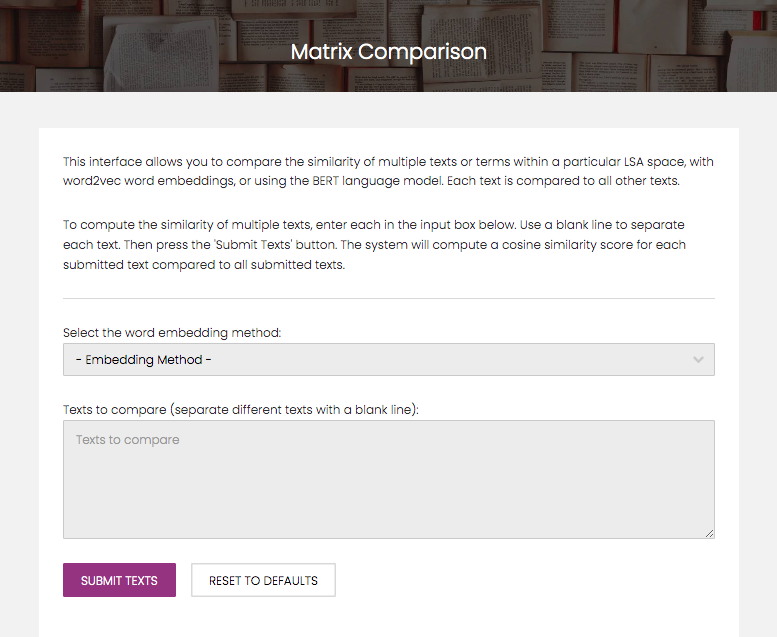
Now we will show what this process looks like within the website interface. First, navigate to the matrix comparison web page, which contains a short instructional header, followed by comparison options and an input field.
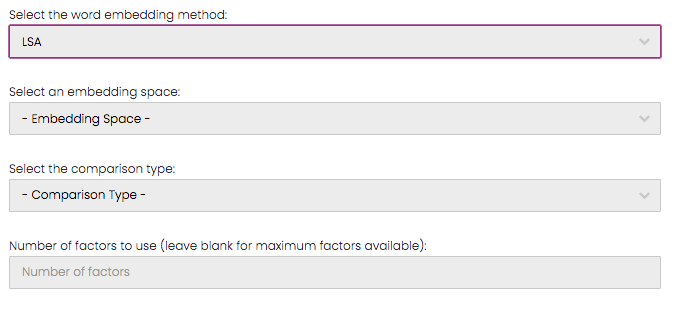
We first need to choose the word embedding method that the comparison should be performed with. The options are LSA, word2vec, and BERT. Say that we would like to perform this comparison of the 4 documents with LSA embeddings, so upon choosing LSA from the first dropdown, a series of other options will be displayed.
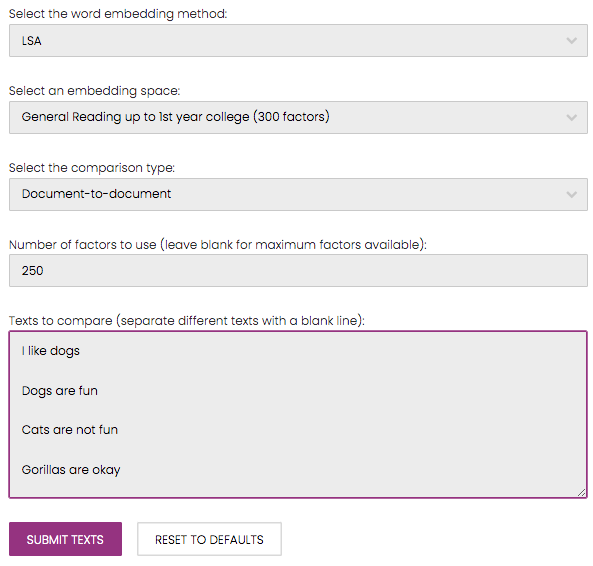
For an LSA comparison, we must determine which embedding space the comparison will be performed in. Each embedding space signifies the corpus that the specific LSA implementation was generated with. See the word embedding informational page for a description of the embedding spaces available to use in this website. Next, the comparison type must be selected. This will determine whether a term-to-term or document-to-document comparison will be performed. Finally, the number of factors to use is entered. This determines how many dimensions of the embeddings are used. This field can be left blank to use every dimension in the original embedding space. Word2vec and BERT implementations simply require a choice of training corpus.
Finally, the documents are entered into the input box, with a blank line used for separation.
The "Submit Text" button sends these inputs to the backend API for matrix semantic similarity comparison and will output the results in a matrix format.
The processes are similar for the one to many, pairwise, and sentence comparisons, with the only difference being how the text is input and how the comparison is completed. The nearest neighbor comparison requires the same parameters, however it accepts a single word or document with which the chosen semantic space is searched for "neighbors" (i.e., individual words that have the closest cosine distance to the source word).